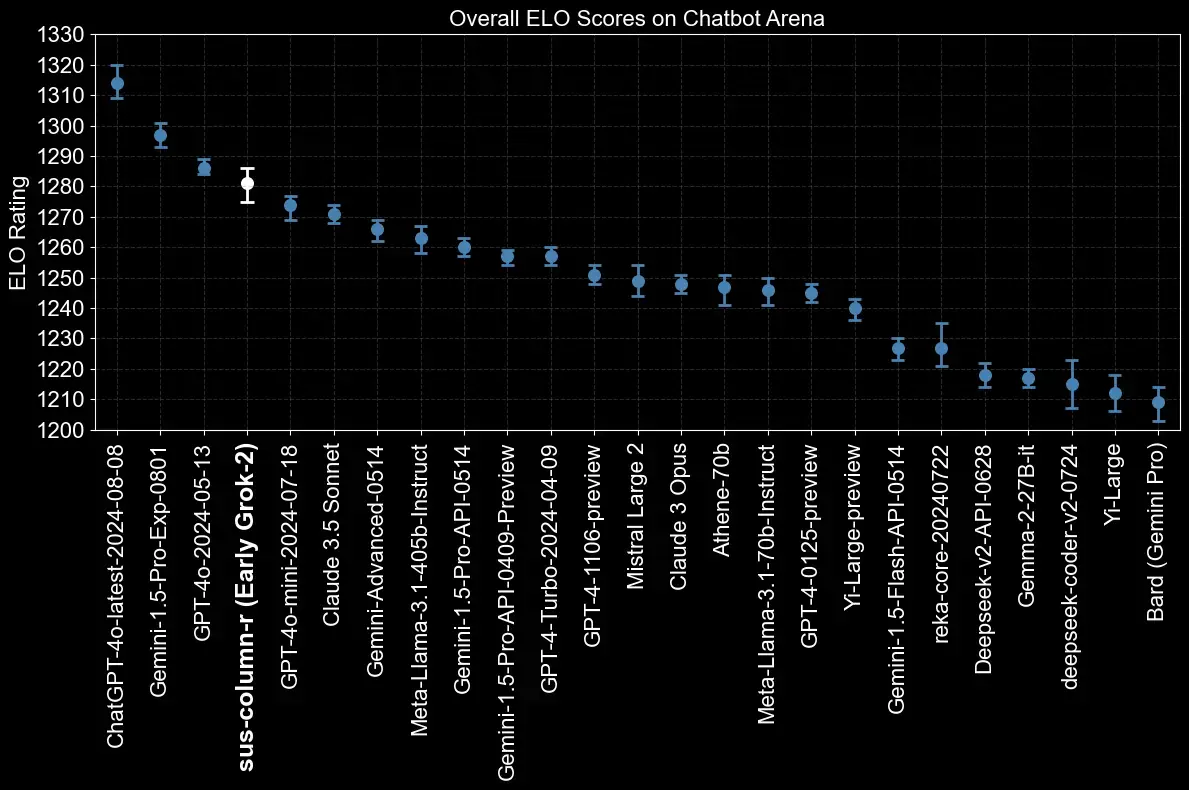
We are excited to release an early preview of Grok-2, a significant step forward from our previous model Grok-1.5, featuring frontier capabilities in chat, coding, and reasoning. At the same time, we are introducing Grok-2 mini, a small but capable sibling of Grok-2. An early version of Grok-2 has been tested on the LMSYS leaderboard under the name "sus-column-r." At the time of this blog post, it is outperforming both Claude 3.5 Sonnet and GPT-4-Turbo.
Grok-2 and Grok-2 mini are currently in beta on 𝕏, and we are also making both models available through our enterprise API later this month.
Grok-2 language model and chat capabilities
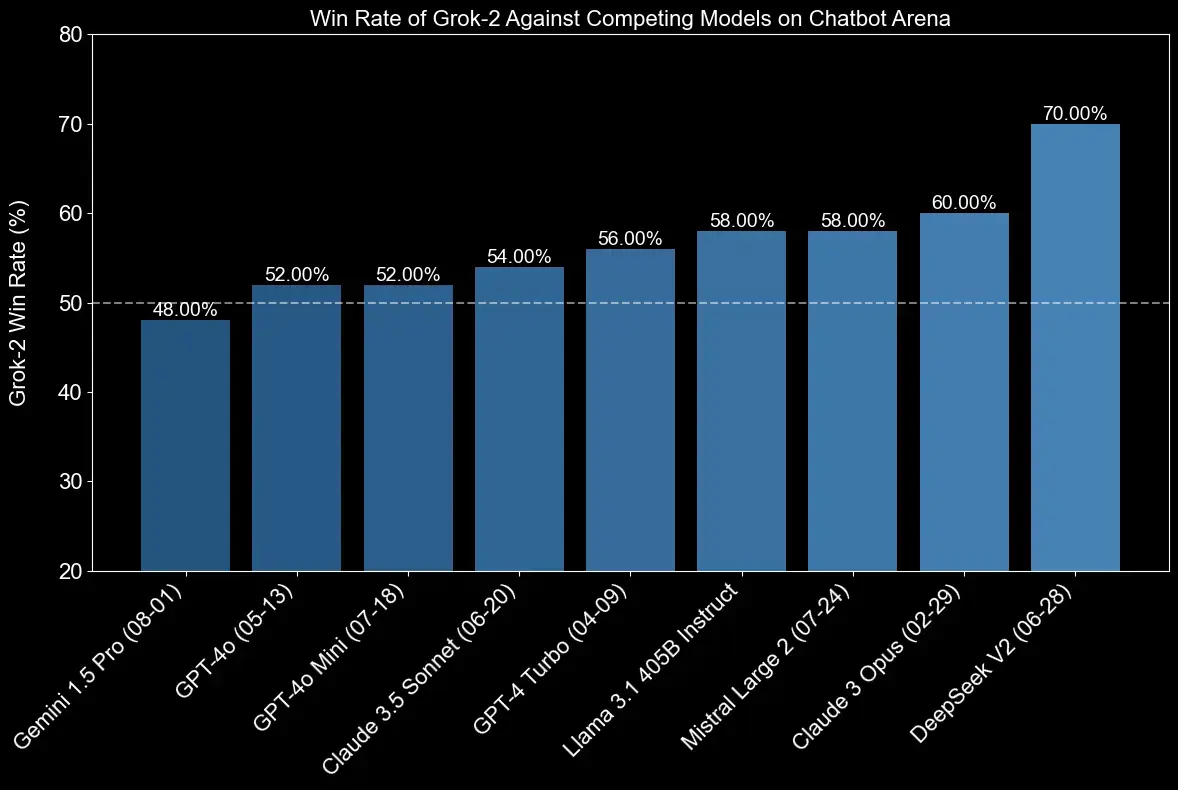
We introduced an early version of Grok-2 under the name "sus-column-r" into the LMArena.ai Chatbot Arena, a popular competitive language model benchmark. It outperforms both Claude and GPT-4 on the LMSYS leaderboard in terms of its overall Elo score.
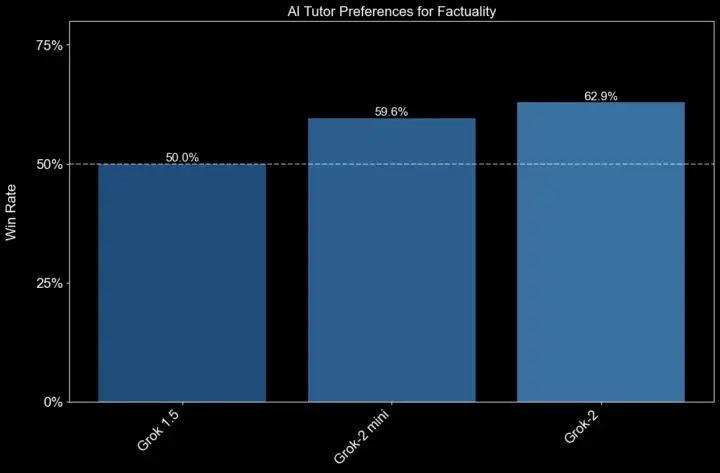
Internally, we employ a comparable process to evaluate our models. Our AI Tutors engage with our models across a variety of tasks that reflect real-world interactions with Grok. During each interaction, the AI Tutors are presented with two responses generated by Grok. They select the superior response based on specific criteria outlined in our guidelines. We focused on evaluating model capabilities in two key areas: following instructions and providing accurate, factual information. Grok-2 has shown significant improvements in reasoning with retrieved content and in its tool use capabilities, such as correctly identifying missing information, reasoning through sequences of events, and discarding irrelevant posts.
Benchmarks
We evaluated the Grok-2 models across a series of academic benchmarks that included reasoning, reading comprehension, math, science, and coding. Both Grok-2 and Grok-2 mini demonstrate significant improvements over our previous Grok-1.5 model. They achieve performance levels competitive to other frontier models in areas such as graduate-level science knowledge (GPQA), general knowledge (MMLU, MMLU-Pro), and math competition problems (MATH). Additionally, Grok-2 excels in vision-based tasks, delivering state-of-the-art performance in visual math reasoning (MathVista) and in document-based question answering (DocVQA).
| Benchmark | Grok-1.5 | Grok-2 mini‡ | Grok-2‡ | GPT-4 Turbo* | Claude 3 Opus† | Gemini Pro 1.5 | Llama 3 405B | GPT-4o* | Claude 3.5 Sonnet† | |
|---|---|---|---|---|---|---|---|---|---|---|
| GPQA | 35.9% | 51.0% | 56.0% | 48.0% | 50.4% | 46.2% | 51.1% | 53.6% | 59.6% | |
| MMLU | 81.3% | 86.2% | 87.5% | 86.5% | 85.7% | 85.9% | 88.6% | 88.7% | 88.3% | |
| MMLU-Pro | 51.0% | 72.0% | 75.5% | 63.7% | 68.5% | 69.0% | 73.3% | 72.6% | 76.1% | |
| MATH§ | 50.6% | 73.0% | 76.1% | 72.6% | 60.1% | 67.7% | 73.8% | 76.6% | 71.1% | |
| HumanEval¶ | 74.1% | 85.7% | 88.4% | 87.1% | 84.9% | 71.9% | 89.0% | 90.2% | 92.0% | |
| MMMU | 53.6% | 63.2% | 66.1% | 63.1% | 59.4% | 62.2% | 64.5% | 69.1% | 68.3% | |
| MathVista | 52.8% | 68.1% | 69.0% | 58.1% | 50.5% | 63.9% | — | 63.8% | 67.7% | |
| DocVQA | 85.6% | 93.2% | 93.6% | 87.2% | 89.3% | 93.1% | 92.2% | 92.8% | 95.2% |
* GPT-4-Turbo and GPT-4o scores are from the May 2024 release.
† Claude 3 Opus and Claude 3.5 Sonnet scores are from the June 2024 release.
‡ Grok-2 MMLU, MMLU-Pro, MMMU and MathVista were evaluated using 0-shot CoT.
§ For MATH, we present maj@1 results.
¶ For HumanEval, we report pass@1 benchmark scores.
Experience Grok with real-time information on 𝕏
Over the past few months, we've been continuously improving Grok on the 𝕏 platform. Today, we're introducing the next evolution of the Grok experience, featuring a redesigned interface and new features.

𝕏 Premium and Premium+ users will have access to two new models: Grok-2 and Grok-2 mini. Grok-2 is our state-of-the-art AI assistant with advanced capabilities in both text and vision understanding, integrating real-time information from the 𝕏 platform, accessible through the Grok tab in the 𝕏 app. Grok-2 mini is our small but capable model that offers a balance between speed and answer quality. Compared to its predecessor, Grok-2 is more intuitive, steerable, and versatile across a wide range of tasks, whether you're seeking answers, collaborating on writing, or solving coding tasks. In collaboration with Black Forest Labs, we are experimenting with their FLUX.1 model to expand Grok’s capabilities on 𝕏. If you are a Premium or Premium+ subscriber, make sure to update to the latest version of the 𝕏 app in order to beta test Grok-2.
Build with Grok using the Enterprise API
We are also releasing Grok-2 and Grok-2 mini to developers through our new enterprise API platform later this month. Our upcoming API is built on a new bespoke tech stack that allows multi-region inference deployments for low-latency access across the world. We offer enhanced security features such as mandatory multi-factor authentication (e.g. using a Yubikey, Apple TouchID, or TOTP), rich traffic statistics, and advanced billing analytics (incl. detailed data exports). We further offer a management API that allows you to integrate team, user, and billing management into your existing in-house tools and services. Join our newsletter to get notified when we launch later this month.
What is next?
Grok-2 and Grok-2 mini are being rolled out on 𝕏. We are very excited about their applications to a range of AI-driven features, such as enhanced search capabilities, gaining deeper insights on 𝕏 posts, and improved reply functions, all powered by Grok. Soon, we will release a preview of multimodal understanding as a core part of the Grok experience on 𝕏 and API.
Since announcing Grok-1 in November 2023, xAI has been moving at an extraordinary pace, driven by a small team with the highest talent density. We have introduced Grok-2, positioning us at the forefront of AI development. Our focus is on advancing core reasoning capabilities with our new compute cluster. We will have many more developments to share in the coming months. We are looking for individuals to join our small, focused team dedicated to building the most impactful innovations for the future of humanity. Apply to our positions here.