
Introducing Grok-1.5, our latest model capable of long context understanding and advanced reasoning. Grok-1.5 will be available to our early testers and existing Grok users on the 𝕏 platform in the coming days.
By releasing the model weights and network architecture of Grok-1 two weeks ago, we presented a glimpse into the progress xAI had made up until last November. Since then, we have improved reasoning and problem-solving capabilities in our latest model, Grok-1.5.
Capabilities and Reasoning
One of the most notable improvements in Grok-1.5 is its performance in coding and math-related tasks. In our tests, Grok-1.5 achieved a 50.6% score on the MATH benchmark and a 90% score on the GSM8K benchmark, two math benchmarks covering a wide range of grade school to high school competition problems. Additionally, it scored 74.1% on the HumanEval benchmark, which evaluates code generation and problem-solving abilities.
| Benchmark | Grok-1 | Grok-1.5 | Mistral Large | Claude 2 | Claude 3 Sonnet | Gemini Pro 1.5 | GPT-4 | Claude 3 Opus |
|---|---|---|---|---|---|---|---|---|
| MMLU | 73% 5-shot | 81.3% 5-shot | 81.2% 5-shot | 75% 5-shot | 79% 5-shot | 83.7% 5-shot | 86.4% 5-shot | 86.8 5-shot |
| MATH | 23.9% 4-shot | 50.6% 4-shot | — | — | 40.5% 4-shot | 58.5% 4-shot | 52.9% 4-shot | 61% 4-shot |
| GSM8K | 62.9 8-shot | 90% 8-shot | 81% 5-shot | 88% 0-shot CoT | 92.3% 0-shot CoT | 91.7% 11-shot | 92% 5-shot | 95% 0-shot CoT |
| HumanEval | 63.2% 0-shot | 74.1% 0-shot | 45.1% 0-shot | 70% 0-shot | 73% 0-shot | 71.9% 0-shot | 67% 0-shot | 84.9% 0-shot |
Long Context Understanding
A new feature in Grok-1.5 is the capability to process long contexts of up to 128K tokens within its context window. This allows Grok to have an increased memory capacity of up to 16 times the previous context length, enabling it to utilize information from substantially longer documents.
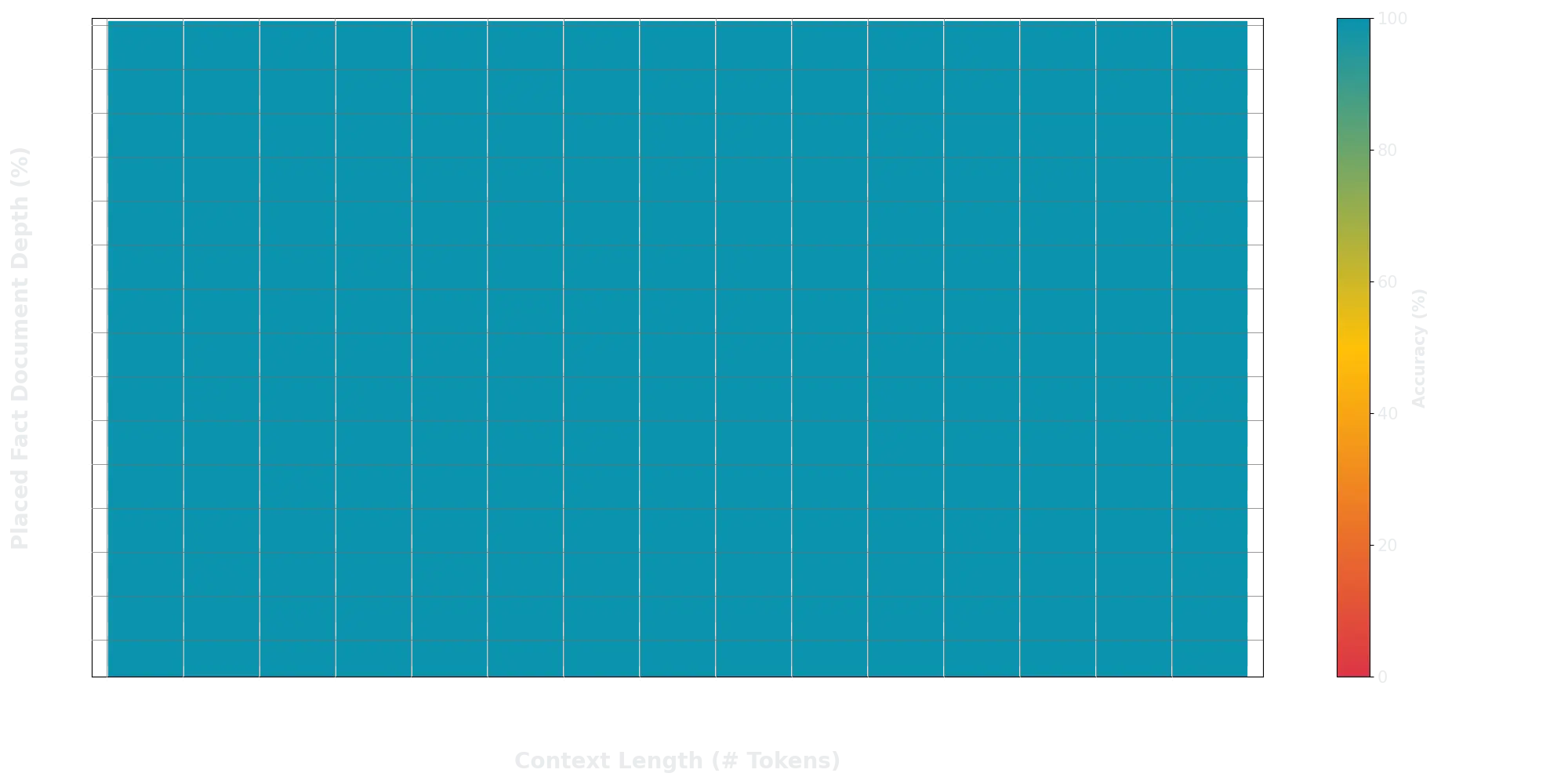
Furthermore, the model can handle longer and more complex prompts, while still maintaining its instruction-following capability as its context window expands. In the Needle In A Haystack (NIAH) evaluation, Grok-1.5 demonstrated powerful retrieval capabilities for embedded text within contexts of up to 128K tokens in length, achieving perfect retrieval results.
Grok-1.5 Infra
Cutting-edge Large Language Model (LLMs) research that runs on massive GPU clusters demands robust and flexible infrastructure. Grok-1.5 is built on a custom distributed training framework based on JAX, Rust, and Kubernetes. This training stack enables our team to prototype ideas and train new architectures at scale with minimal effort. A major challenge of training LLMs on large compute clusters is maximizing reliability and uptime of the training job. Our custom training orchestrator ensures that problematic nodes are automatically detected and ejected from the training job. We also optimized checkpointing, data loading, and training job restarts to minimize downtime in the event of a failure. If working on our training stack sounds interesting to you, apply to join the team.
Looking Ahead
Grok-1.5 will soon be available to early testers, and we look forward to receiving your feedback to help us improve Grok. As we gradually roll out Grok-1.5 to a wider audience, we are excited to introduce several new features over the coming days.
Note that the GPT-4 scores are taken from the March 2023 release. For MATH and GSM8K, we present maj@1 results. For HumanEval, we report pass@1 benchmark scores.